

Fear Not The AI, But The Automation - Your Job Is Next
23.05.2026
A data scientist – let's call him Milo – is
tasked with building a predictive model for fraud detection. And though he is
not very familiar with the fraud domain and isn't a seasoned data scientist, he
likes the idea of learning something new, so he jumps on to the task
immediately.
He dives into the Datawarehouse (DWH) and locates the table with recent and historical transactions. He pulls the last six months of the data aside to his development area and pronounces this table as his initial Analytical Base Table (ABT). This dataset will be used to train and validate his predictive model.
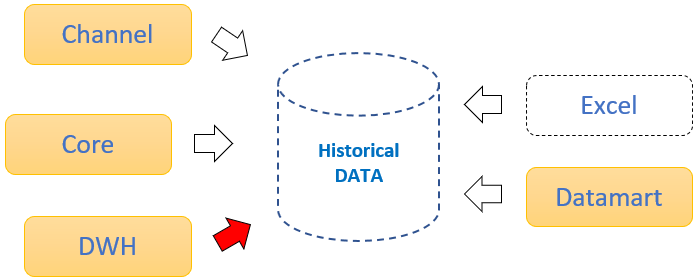
But at this point, it's still missing one
critical detail – an indicator of fraud. If we want the model to spot the scams
among genuine transactions, we must first be able to distinguish them from each other (flag them as fraud or non-fraud). How else would the model be able to differentiate between the indicators of "good"
and "bad" transactions, right? Unfortunately, Milo doesn't know where
such information might be stored in DWH (or if it is even there), nor is he
aware of any specific data mart holding such information. Therefore, he needs
to reach out to his colleagues in the Fraud Risk department. Milo sees them immediately and asks them whether they have a six months history of fraud to which they
respond with an approving nod. "Amazing news then, let me have it!" –
says Milo. A fraud risk department colleague was initially a bit reluctant as any
knowledge related to prior frauds, fraud preventive measures, processes, and
controls are strictly shared on a need-to-know basis. This information is kept only
within the fraud risk department, but after checking with relevant superiors,
he provided Milo with an excel sheet of fraud cases for the last six months.
Milo is hyped as he seems to move quickly ahead with his task, but when he opens the sheet, he realizes that it might not be as smooth as he expected. The Excel sheet does have interesting information like the loss amount, the amount recovered, the date of the incident, the source of the incident, customer ID, and a few other details. But Milo is missing the most important information for him – the actual transaction ID so he can match and flag the transactions in his dataset which were identified as fraudulent. On the other hand, the good news was that the excel sheet contained at least some details of transactions linked to the fraud cases. Milo did check again with his colleagues whether they might have data where actual transaction IDs are assigned to the frauds but with no luck this time. Since having the flags is the only way to move forward with building the predictive model, he decided to review the excel sheet and manually match and flag the fraudulent transactions in his dataset. It did take him some time to go through all six months of fraud cases and flag the transactions, as there were a few hundred of them. But at last, the ABT was ready.

Milo opened his analytical toolset to
perform the first test and try to develop a predictive analytical model. He did
have the transactions with a few hundred fraud cases tagged, so this should be pretty
straightforward. Next, Milo divided the ABT into two datasets - training and
validation. The training dataset will be used to train the data, and the latter
will be used to validate the accuracy of the predictive model.
Milo is not a seasoned data scientist, but he already knows that using only information which are part of the transactional data might not be sufficient for building a robust and stable model. So, he was not surprised when the model selected relevant fields as the "Tnx. Amount" and "Tnx. Type". Of course, the model built around such limited fields had to be somewhat inaccurate. But since the process of creating the model is repetitive and expects multiple rounds of adjustments and validations, this was to be expected as the first step. Milo's next step was to include additional details to complement the transactional data and allow a finer distinction between "good" and "bad" transactions.
Milo added customer-related details – "Age",
"How long the customer was with the bank", and "Segment to which
the customer belonged". So now every transaction in the ABT has these extra
columns populated based on the linked customer. After adding these details, he
re-trained the model again and saw that the model seemed to consider age as a
relevant indicator – it appeared that older customers were slightly more common
among the victims of the fraud.
In the next round, Milo added further details – now he added points related to the accounts and products – what products customers had – cards, loans, savings accounts. All of these details were appended to each transaction within ABT. Milo again re-trained the model, and it seemed that customers with loans were slightly more targeted as the victims of the fraud. But overall accuracy of the model was improving only very little.
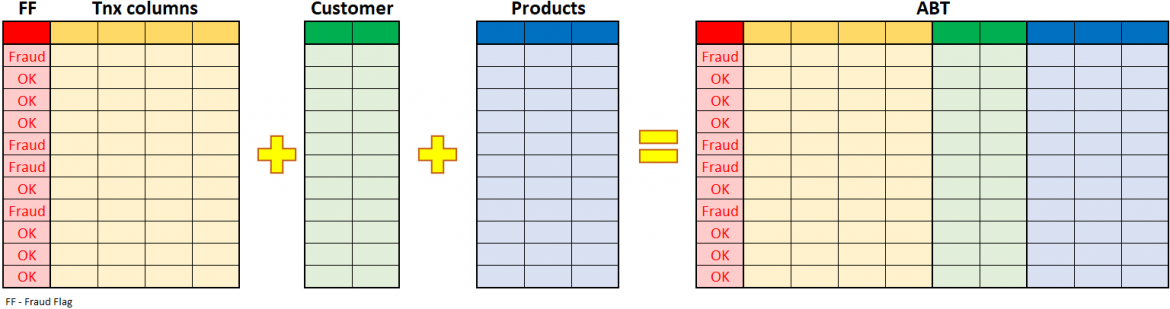
Milo has amended the ABT with all the
different information from many other tables of the DWH, yet the model's
accuracy wasn't very high. Nevertheless, he felt a bit stuck, so he told his
fraud-risk colleagues what he had learned so far. Colleagues confirmed his findings
around elderly people and people with loans as well with a bit of extra vital information
– customers with loans which were flagged in the provided excel were mainly linked
to the "application fraud," which was in the majority a 1st party fraud. So they were not victims but rather
perpetrators.
This was exciting information as Milo had seen some fraud classification details in the excel sheet, but he didn't consider it relevant at the time. Now he remembered that in excel, there were different fraud typologies with very different meanings and logically with very different fraud patterns. He realized he was trying to build a model that would capture different fraud typologies. Now he understood why his model's accuracy was not meeting his expectations.
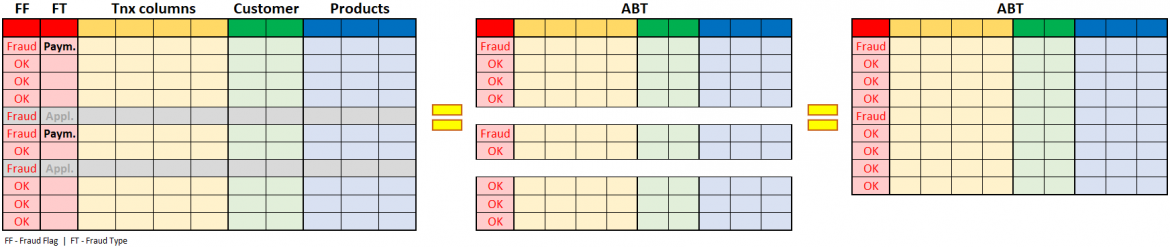
Unfortunately, this meant that he had to go
through excel again and not only flag the transactions as fraudulent or not but
also amend the data with the fraud typology column to distinguish between
different fraud types. After doing this, he decided to focus only on payment
fraud and ignore all the other typologies to make his model more focused and
accurate. By doing this, he also realized that the pool of fraudulent
transactions decreased substantially, and from hundreds of fraudulent
transactions, he was down to slightly more than a hundred. A lower number of
frauds in the population often results in lower accuracy of predictive models. The
more fraudulent transactions, the better, so the model can spot different variants
of "bad" transactions.
After re-training the model on the new ABT, his model's accuracy improved (even though having a loan wasn't a relevant indicator of fraud anymore). However, it still wasn't good enough as with the current False-Positive Ratio (FPR); the model would create a lot of friction and result in many customer complaints.
Will Milo create the final model now? Are there any further actions that could improve the model?














{kind=link}